Subscribe and Share
-
 @industrydocs on Twitter
@industrydocs on Twitter
-
 Opioids Industry RSS Feed
Opioids Industry RSS Feed
-
Subscribe to Newsletter
Links
Thursday, December 19, 2024
Teva and Allergan Documents
OIDA staff added 235,705 documents to its newest collection, the Teva and Allergan Documents. This batch brings the collection to over 1 million documents and includes sales training presentations, marketing communications, and more.
The Teva and Allergan collection will encompass about 1.9 million documents when complete. Processed documents are being made public on a rolling basis with monthly releases expected through 2025.
New Teva and Juul Labs Documents Posted!
Opioid Industry Documents ArchiveTeva and Allergan Documents
OIDA staff added 235,705 documents to its newest collection, the Teva and Allergan Documents. This batch brings the collection to over 1 million documents and includes sales training presentations, marketing communications, and more.
The Teva and Allergan collection will encompass about 1.9 million documents when complete. Processed documents are being made public on a rolling basis with monthly releases expected through 2025.
Truth Tobacco Industry Documents
Juul Labs Collection
117,000+ new documents were posted to the Juul Labs Collection today. This brings the collection to over 2.9 million documents and includes social media reports, marketing campaigns, product complaint logs, product design materials, and more.
In partnership with the University of North Carolina at Chapel Hill Libraries, the IDL continues to process and make available documents subject to public disclosure under JUUL Labs’s 2021 settlement with North Carolina.
Tuesday, December 17, 2024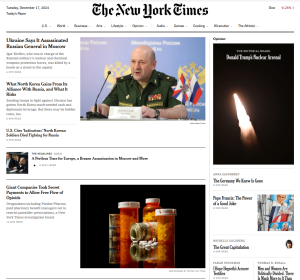
Opioid Archive Documents on PBMs
Check out “Giant Companies Took Secret Payments to Allow Free Flow of Opioids,” a wonderful in-depth investigation (and use of Opioid Archive documents!) on pharmacy benefit managers (PBMs) by Chris Hamby for the New York Times. Learn more about interactions between PBMs and opioid manufacturers like Purdue and Mallinckrodt.
A compilation of OIDA documents cited in the article:
- “Offer rebates to remove payer restriction” (see p88 of slide deck)
- “This is a best practice of how to reverse a negative decision”
- “The restrictions, the company noted in an internal planning document, will ‘create barriers to OxyContin being able to achieve significant growth’” (see p12)
- “We need to remove the barrier to growth, and that will require us to ‘pay to play’”
- “But after ‘assertive action’ by Mallinckrodt and a P.B.M. called Prime Therapeutics, the Blue Cross Blue Shield plan ‘quickly reversed the decision’” (see p6 of slide deck)
- “CVS Caremark negotiated an option that allowed clients to set a lower limit, but if they did, the rebate that they received from Purdue would be cut roughly in half.”
- “‘Make sure you let all your physicians know’ that ‘they are free to write’ prescriptions without insurance obstacles”
- “‘This is a “no-win/tough” decision,’ a Purdue executive wrote to colleagues”
- “According to an internal Purdue memo, the drugmaker agreed to keep paying because it feared that it would be booted from the middleman’s drug lists altogether ‘if we do not keep them whole in terms of rebates.’”
For another perspective on PBMs and the opioid crisis, read Catherine Dunn's October article in Barron's, Confidential Files Detail PBMs’ Backroom Negotiations—and Their Role in the Opioid Crisis.
Thursday, November 21, 2024
As you may be aware, the Internet Archive has recently faced a series of cyberattacks, prompting them to enhance security measures, strengthen firewalls, and update software. Unfortunately, these challenges have temporarily prevented the upload of multimedia items, impacting our last two document releases (October and November 2024).
We are closely monitoring the situation and maintaining communication with the Internet Archive team. Once uploading can resume, we will begin posting the audio and video files from our latest collection additions.
November 2024 Updates - New Opioid and JUUL Documents
Opioid Industry Documents Archive - Teva and Allergan Documents
OIDA staff added 259,000+ documents to its newest collection, the Teva and Allergan Documents. This batch brings the collection to more than 848,000 documents and includes sales training presentations, marketing communications, and more.
The Teva and Allergan collection will encompass about 1.9 million documents when complete. Processed documents are being made public on a rolling basis with monthly releases expected from 2024-2026.
Announcing the OIDA Data Products
Explore our newest resource, OIDA Data Products — tools that can facilitate and inspire research.
We created these datasets to provide access points for data analysis of Opioid Industry Documents. Researchers get a running start on exploring data, benefiting from our work to curate and deduplicate documents, provide a glossary of spreadsheet column names, and more. Users can craft queries online or select a subset of the data for download, allowing them to interact with OIDA data before dedicating time and resources to a full analysis.
“OIDA Data Products reduces some of the barriers to working with OIDA data, helping researchers get a sense of the many gems hidden among OIDA’s millions of documents,” said Kevin Hawkins, OIDA program director for Johns Hopkins University. “Working with data wranglers, statisticians, and developers, we hope these data products will facilitate new research, helping us to better understand the opioid crisis.”
To learn more and access OIDA Data Products, visit https://data.oida-resources.jhu.edu/. 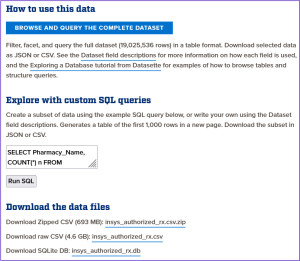
Tobacco Industry Documents Archive - Juul Labs Collection
151,000+ new documents were posted to the Juul Labs Collection today!
This new batch of documents includes social media presence reports, marketing campaigns, focus group findings, product design, and more.
In partnership with the University of North Carolina at Chapel Hill Libraries, the IDL continues to process and make available documents subject to public disclosure under JUUL Labs’s 2021 settlement with North Carolina.
An update regarding our audio-visual files:
The IDL partners with the excellent Internet Archive to host the audio and video files found in our industry documents archives.As you may be aware, the Internet Archive has recently faced a series of cyberattacks, prompting them to enhance security measures, strengthen firewalls, and update software. Unfortunately, these challenges have temporarily prevented the upload of multimedia items, impacting our last two document releases (October and November 2024).
We are closely monitoring the situation and maintaining communication with the Internet Archive team. Once uploading can resume, we will begin posting the audio and video files from our latest collection additions.
New Papers and Publications
-
Brian Gac, Kgosi Tavares, Hanna Yakubi, Hannah Khan, Dorie Apollonio, Eric Crosbie.
Pharmaceutical industry use of key opinion leaders to market prescription opioids: A review of internal industry documents, 2024 November. Exploratory Research in Clinical and Social Pharmacy.
Wednesday, November 20, 2024
Introducing OIDA Data Products
The Opioid Industry Documents Archive (OIDA), a collaborative undertaking between the University of California, San Francisco and Johns Hopkins University, invites you to explore our newest resource, OIDA Data Products—tools that can facilitate and inspire research.
We created these datasets to provide access points for data analysis of OIDA documents. Researchers get a running start on exploring data, benefiting from our work to curate and deduplicate documents, provide a glossary of spreadsheet column names, and more. Users can craft queries online or select a subset of the data for download, allowing them to interact with OIDA data before dedicating time and resources to a full analysis.
“OIDA Data Products reduces some of the barriers to working with OIDA data, helping researchers get a sense of the many gems hidden among OIDA’s millions of documents,” said Kevin Hawkins, OIDA program director for Johns Hopkins University. “Working with data wranglers, statisticians and developers, we hope these data products will facilitate new research helping us to better understand the opioid crisis.”
Current OIDA Data Products include:
- Insys Authorized Prescriptions
- Purdue Sales Visit Data
- Mallinckrodt Sales Visit Data
- Deduplicated Spreadsheets
OIDA was launched by UCSF and Johns Hopkins in March 2021 as a free public resource. The digital repository includes publicly disclosed documents arising from litigation brought against opioid manufacturers, distributors, pharmacies and consultants by local and state governments and tribal communities.
The Archive contains more than 17.9 million pages in 3.8 million documents and is expected to continue to grow for years to come. Documents are full-text searchable and include an array of relevant materials from many different companies, including emails, memos, presentations, sales reports, budgets, audit reports, Drug Enforcement Administration briefings, meeting agendas and minutes, expert witness reports and trial transcripts.
OIDA may be of use to many different parties, including individuals and communities harmed by the opioid crisis, as well as the media, health care practitioners, students, lawyers, and researchers. Major news outlets such as the Washington Post and New York Times and academic resources like Health Affairs Scholar and the American Journal of Public Health have published investigative reports and analysis using OIDA documents.
To learn more and access OIDA Data Products, visit https://data.oida-resources.jhu.edu/.
Monday, November 11, 2024
Behind the Scenes of the OIDA Image Collection
The team behind the UCSF-JHU Opioid Industry Documents Archive was pleased to release its latest OIDA resource in late October: the OIDA Image Collection. This incredible new resource highlights images extracted from documents created by the opioid industry. Many of these documents were designed for internal company audiences and board members, while others were targeted to prescribers and consumers. The images provide insight into corporate practices that shaped the opioid crisis.
The OIDA Image Collection currently features 3,907 images extracted from PowerPoint and Excel documents in OIDA. How did we select these images? And how did we create metadata like titles, descriptions, and categories to help you browse and find images of interest? It was a complicated process involving a mix of automated and manual steps.
Selecting the images
First, we processed all PowerPoint and Excel documents in OIDA as of December 2023 to remove every image embedded in these documents – roughly 4 million images!
Second, we ran some code that removed:
- Images whose original filename included “thumb” (likely indicating a low-resolution thumbnail of little value)
- images with a width or height of less than 200 pixels (likely too small to be useful)
- images with an entropy score of less than 6.0 (likely indicating a gradient horizontal rule, background image, or other meaningless decoration)
This yielded roughly 100,000 images.
Third, we deduplicated the images found, tracking the source documents so that in the OIDA Image Collection website we could link to all documents in the archive where the image was found. This step left us with just 13,688 images. This dramatic drop is due in part to the fact that OIDA often contains more than one copy of the same email attachment and each version of the document circulated by company employees.
Fourth, our metadata librarian reviewed these 13,688 images to decide which to keep according to our subjective criteria for inclusion. The criteria were refined over time with input from a number of OIDA team members, but in the end, we decided to discard the following:
- purely decorative images
- bare logos and branding templates
- headshots
- text-heavy images
- computer screenshots
- illegible or meaningless images
- sexually explicit images
Finally, we were left with the 3,907 images that we’ve made available in the collection.
Describing the images
We used a mix of AI models and human expert review to generate metadata to help users browse and search for images.
- Title: So far we have only been creating these by hand, so not all images have a Title at this time. We are considering using AI to generate titles in the future.
- Description: We generated these using Microsoft’s Florence-2 AI model, and our metadata librarian, with help from our collection archivist, is reviewing these for typos, nonsensical statements, inaccuracies, and more. When we make small corrections, we leave them labeled with the “AI” badge in the website interface, but if we rewrite from scratch, we remove the AI badge.
- Type: We generated these using OpenAI’s CLIP AI model, but our metadata librarian reviewed these and made corrections to about 40% of the AI-assigned values.
- Category: Our metadata librarian assigned these by hand.
Making the images available online
The OIDA Image Collection website runs on an instance of WordPress, with the images themselves served from a content delivery network (CDN) to increase performance of the site and ease the process of updating the website. We hired Mission Media, a web agency familiar with creating polished websites that follow university branding requirements, to build the website.
The website’s search feature uses not just the metadata fields but also the text within the image, which we generated using optical character recognition (OCR).
Next steps
AI models are rapidly developing, so we expect to get better results when we use them in the future. One way you can help us with that is by participating in our collaboration with Hugging Face to test multiple AI models for writing image descriptions (captions). While no model is perfect, we want to know which is our best starting point for generating descriptions for images in the future.
We are also considering adding new features to the website, like allowing user corrections and annotations and improving the “related images” feature to be based on the image files themselves rather than just the metadata. And we might adjust the entropy score used at the filtering stage to be less aggressive in removing images before human review.
Over the past few months, the OIDA team has added nearly 600,000 documents from Teva to the archive, with many more to come from this and other companies. We also plan to expand our image detection and classification techniques beyond PowerPoint and Excel documents to the many other file formats found in OIDA. So we hope to mine the archive for many more images to add to the OIDA Image Collection, providing an even richer view on how opioids and their effects were represented or misrepresented to patients and prescribers, and more broadly how the drug crisis was imagined and perpetuated by the industry while it unfolded.
Thursday, October 31, 2024
October 2024 Updates - New Opioid and JUUL Documents
Collection Updates
Opioid Industry Documents Archive - Teva and Allergan Documents
OIDA staff added 218,267 documents to its newest collection, the Teva and Allergan Documents. This batch brings the collection to more than 588,000 documents and includes sales training presentations, interviews with prescribers, reports on focus groups, product communications, and more.
The Teva and Allergan collection will encompass about 1.9 million documents when complete. Processed documents are being made public on a rolling basis with monthly releases expected from 2024-2026.
Announcing the OIDA Image Collection and How You Can Help!
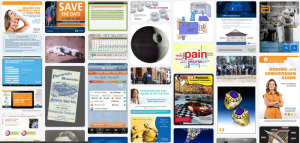
We are proud to introduce the OIDA Image Collection, a website created to highlight images within the OIDA documents. Images provide unique entry points to understand a visual narrative of the opioid industry and gain insight into harmful corporate and marketing practices that contributed to the opioid crisis. Researchers can browse, limit their results by filters, and search by keyword. By viewing the source documents, you can see the images in their original context.
The OIDA team used artificial intelligence (AI) to write captions for highlighted images within the OIDA Image Collection but we could use your help! We have generated captions using two different AI models and need to decide which AI-generated caption is better for use in the OIDA Image Collection. Thanks to support from Hugging Face, a platform for collaborating on models and datasets for machine learning, and its Argilla data annotation tool, we have created a handy interface for voting on the quality of image captions. To help us out, you’ll just need to create a free Hugging Face account.
Your image labeling efforts will contribute to an open preference dataset, crucial for "steering" AI models towards generating more useful outputs in specific domains. Please email opioidarchive@jh.edu with any questions.
Tobacco Industry Documents Archive - Juul Labs Collection
117K new documents were posted to the Juul Labs Collection today!
This new batch of documents includes social media presence reports, marketing campaigns, focus group findings, product design, and more.
In partnership with the University of North Carolina at Chapel Hill Libraries, the IDL continues to process and make available documents subject to public disclosure under JUUL Labs’s 2021 settlement with North Carolina.

2019 SRNT slide deck.
Education & Research Updates
World Digital Preservation Day – 7 November 2024
Each year, the Digital Preservation Coalition promotes World Digital Preservation Day, which falls on the first Thursday of November.
In line with this year’s theme of 'Preserving Our Digital Content: Celebrating Communities,' the UC Libraries’ Digital Preservation Working Group (DPWG) is hosting a community-building Open House event which presents an opportunity for everyone to learn more about digital preservation while also sharing their own stories and experiences in this space.
Please join the event online on November 7, 2024 from 11AM – 12PM where you’ll hear digital preservation stories from us at the UCSF Industry Documents Library as well as the UC & Jepson Herbaria.
Register via Zoom.
Annual Tobacco and Other Industry Documents Workshop: Recording Now Available!
IDL and the UCSF Center for Tobacco Research and Education (CTCRE) held the "Annual Tobacco and Other Industry Documents Workshop" virtually on October 8th from 9 am-12:15 pm PT.
If you didn't have a chance to join us, the event recording is now available
New Papers and Publications
- Freyja Chapman. Corporate-Government Alliances in Climate Denialism and Solutionism: The Canadian Context, 2024 October. NiCHE; Network in Canadian History & Environment.
- Ravi Gupta; Jason Chernesky; Anna Lembke; et al. The opioid industry's use of scientific evidence to advance claims about prescription opioid safety and effectiveness, 2024 October. Health Affairs Scholar.
- Pedro Nakamura. Juul considered launching a “low-cost vape” in Brazil and selling it in bars and neighborhood markets (in Portuguese); Juul avaliou lançar “vape de baixo custo” no Brasil e vendê-lo em botecos e mercados de bairro, 2024 September. O Joio e O Trigo.
Thursday, October 31, 2024
OIDA Collaboration with Hugging Face on AI Captioning
The recently launched OIDA Image Collection highlights images found within OIDA and includes a description of each image, but it would have taken an enormous amount of time to write a description for each image. Therefore, the OIDA team used artificial intelligence (AI) to write captions for these images to make them more discoverable in the OIDA Image Collection.
But we need your help! We have generated captions using two different AI models and need to decide which AI-generated caption is better for use in the OIDA Image Collection. Thanks to support from Hugging Face, a platform for collaborating on models and datasets for machine learning, and its Argilla data annotation tool, we have created a handy interface for voting on the quality of image captions. To help us out, you’ll just need to create a free Hugging Face account.
Your image labeling efforts will contribute to an open preference dataset, crucial for "steering" AI models towards generating more useful outputs in specific domains.
“Projects like this ensure AI becomes useful for a wider range of audiences, aligning with Hugging Face’s mission to democratize machine learning and make AI more accessible and impactful across diverse fields,” said Daniel van Strien, machine learning librarian at Hugging Face and OIDA National Advisory Committee member.
Vision Language Models (VLMs) represent a cutting-edge field in AI, and your contributions will enable the development of more specialized models for important applications such as captioning large archival image collections. By participating, you're not just helping OIDA – you're shaping the future of AI to better serve specialized communities and enhance visual information accessibility for a wider range of document types.
